


what is pagination
pagination is a technique used to manage large sets of data by breaking them down into smaller, manageable chunks called pages. Pagination is commonly used in APIs to improve performance, reduce response times, and enhance user experience when dealing with large datasets.
Limit and Offset: Pagination typically involves using two parameters: LIMIT and OFFSET.
- Limit: Specifies the maximum number of records to return in each page.
- Offset: Specifies the starting point of the records to return in the result
implementation in studio – step by step process
I utilized database connectors to implement and elucidate the upcoming functionalities. Following that, I created the system layer for canvassing the functions that I developed. I provided hands-on steps and screenshots for a concise explanation.
Create the flow in anypoint studio.
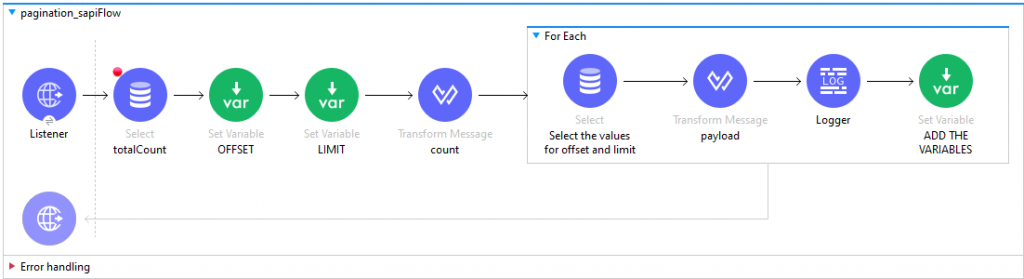
I started the process by counting the total number of data entries using a select operation that was configured in the database. For this particular operation, I utilized a data set consisting of ninety entries. The reason for counting the data initially was to facilitate the use of offset and limit functions more efficiently.
Refer to the screenshot of the select connector below for implementation details:
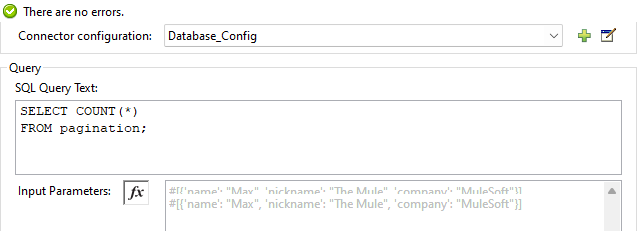
Counted all records using a SELECT statement. By utilizing the count(*) function, I was able to tally up the entire set of ninety data entries as an integer. This method allowed me to accurately gauge the total number of records available.
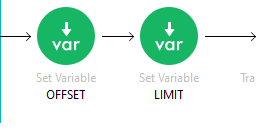
Set up two variables for pagination, specifically using the parameters “OFFSET” and “LIMIT.” These parameters are essential for controlling how data is paginated in a database query.
I could effectively manage the number of records retrieved at once and specify the starting point for the data retrieval. This approach made it easier to handle large data sets and navigate through the records in a more efficient and structured manner.
Let me explain about the both parameters:


- Offset: This parameter specifies the starting point of the data to be returned in the output. In my case, I set the initial offset value to 0, which means the data retrieval begins from the 0th index. This allows me to control where the data extraction starts within the dataset.
- Limit: This parameter determines the maximum number of records to return on each page. I set the limit value to 10, ensuring that each page contains exactly 10 records. This setup allows for consistent and manageable pages of data as users navigate through the dataset.
Transform operation to count iterations and execute a function. This involved using a specific function, ‘to’, that treats a string as an array of characters.
I started the iteration process from 1 using the ‘to’ function, which allowed me to handle data as a range. This setup provided a way to specify the sequence for data processing.
I calculated the number of iterations needed by dividing the total count of records by the limit. Since the total count was accessible in the payload, I referred to it as “payload.count.” To determine the exact number of iterations, I used the ‘ceil’ function to round the divided value up to the nearest whole number. This approach ensured that I accounted for any partial iterations and allowed me to determine the number of iterations required for the function.
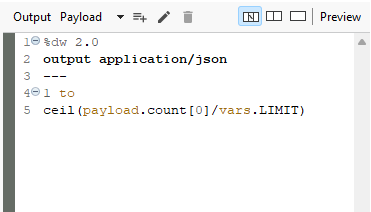
foreach:
Foreach loop for the iteration function to handle paginated data effectively.
After setting up the necessary parameters and functions, I used a loop to iterate through the data. Each iteration processed a specific paginated size of data, which allowed me to handle the data in manageable chunks.
I incorporated various components to execute the iteration function. These components enabled me to perform the necessary operations on each batch of data, such as processing the retrieved records and preparing them for further use or manipulation.
I was able to iterate through the data efficiently, ensuring that each chunk of data was handled appropriately during each iteration. This approach made the process of working with large data sets more structured and streamlined.
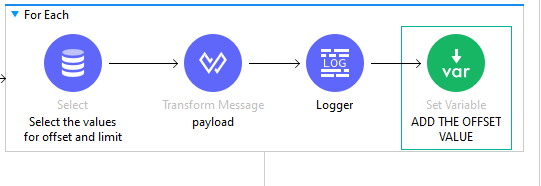
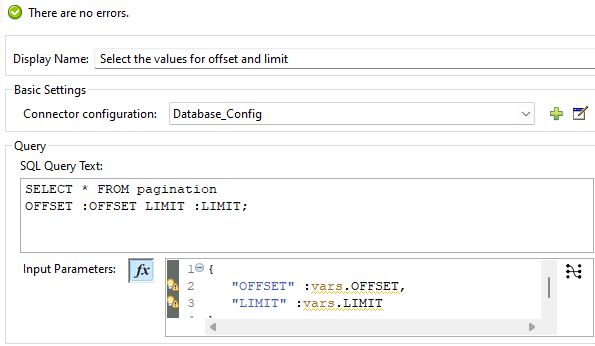
SELECT COMPONENT:
Select component to dynamically adjust the offset and limit values during function execution.
The select component played a crucial role in selecting the offset and limit values in a dynamic format. By allowing these values to be adjusted based on the current state of the function, I was able to modify the range of data being retrieved in real time.
This dynamic approach offered greater flexibility during data processing. By having the ability to change the offset and limit values as needed, I could tailor the data retrieval process to suit specific requirements, such as adjusting the range of data based on user input or other operational needs.
The select component’s dynamic handling of offset and limit values made the function more versatile and adaptable, improving the overall efficiency and effectiveness of the data processing flow.
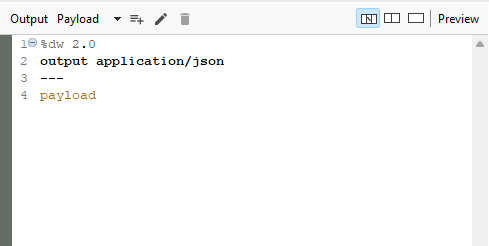
Transform operation to set and convert data into an actual payload for further processing.
After dynamically adjusting the offset and limit values using the select component, I once again used a transform operation. The purpose of this transform was to format and structure the retrieved data as an actual payload.
By converting the data into the expected payload format, the function could easily handle and manipulate the data as required. This transformation step was crucial for ensuring that the data conformed to the expected structure and could be used effectively in subsequent processing stages.
The transform operation not only facilitated data formatting but also helped maintain consistency across the function’s different steps. By setting the payload correctly, I was able to streamline the data processing workflow and improve the overall performance of the function.

Used a logger component to print output data to the console, aiding in monitoring and debugging the data processing function.
After transforming the data into an actual payload, I utilized a logger component to output the data to the console. This process involved setting the value to “payload,” ensuring that the console displayed the data in its structured format.
Using the logger component in this way allowed me to observe the data at each iteration and verify the function’s accuracy and effectiveness. By monitoring the output data in real time, I could easily identify any discrepancies or issues during data processing and address them promptly.
The logger component proved to be a valuable tool for tracking the progress of the function and gaining insights into the data being processed. Its ability to print the payload to the console provided a clear view of the data and helped streamline the debugging and verification process.
Finally, we set one variable for to add the values of both variables.
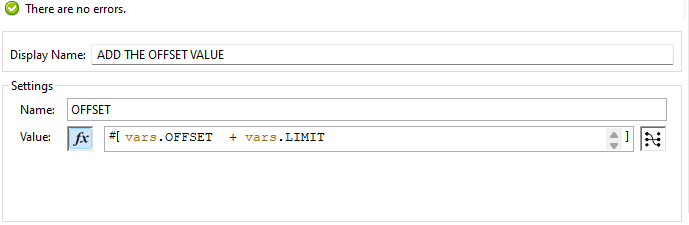
The logger component to add the iteration count to the data, enabling the aggregation of paginated data across multiple iterations.
The logger component played a key role in this process by tracking and displaying the iteration count as each set of data was processed. By maintaining a running count of the iterations, I could ensure that all paginated data was included in the final output.
This approach allowed me to monitor the progress of data processing and verify that each iteration’s data was being correctly added to the overall result. By tracking the iteration count, I could ensure that all parts of the data set were processed sequentially and aggregated as intended.
As each iteration’s data was processed and logged, it became easier to review the data and verify its accuracy. This method of adding the iteration count provided a reliable way to combine paginated data into a comprehensive whole, facilitating efficient and organized data handling.




